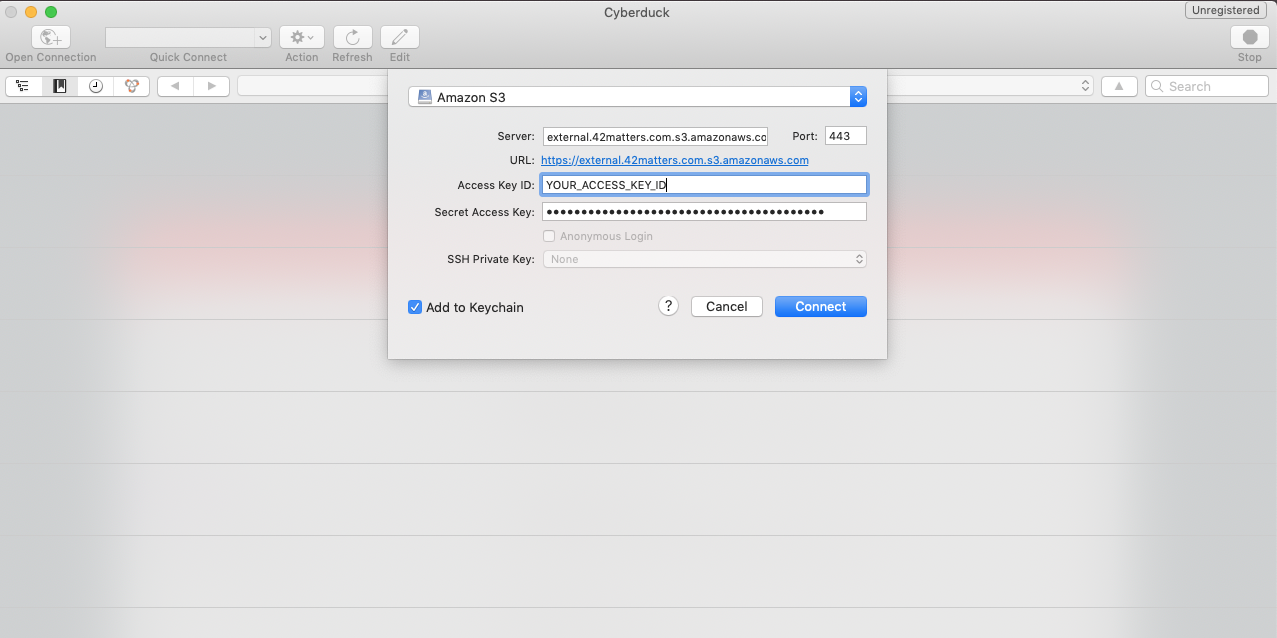
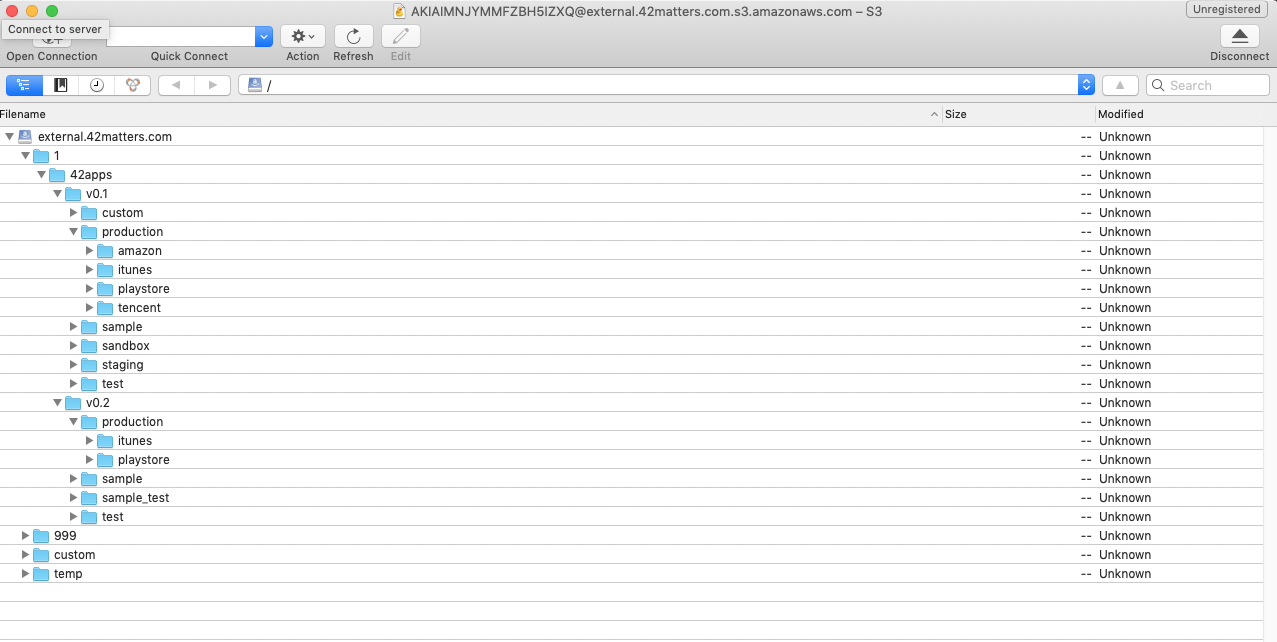
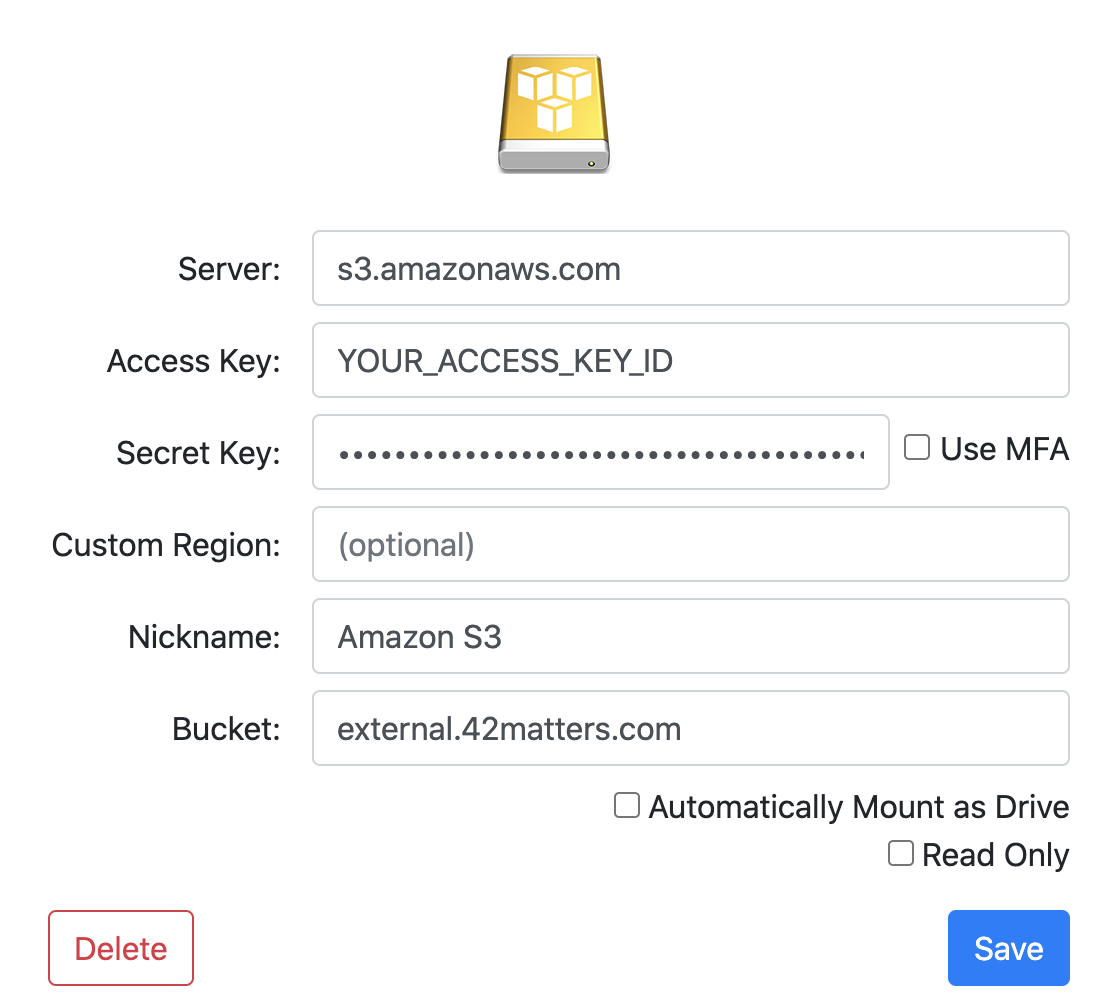
Automate Your Workflow With 42matters’ APIs
Integrate app data and intelligence into your existing workflows, dashboards, CRM platforms, messaging platforms, and more! Below is a selection of the third-party services that are compatible with 42matters’ APIs:

Salesforce

HubSpot

Slack

Intercom

Pipedrive

Zendesk

Gekoboard

Klipfolio
Dynamics